Почему очень полезно делать тесты ДНК в нескольких компаниях
Помимо очевидного всем факта: разные компании имеют разную клиентскую базу и тем самым круг поиска совпаденцев у вас расширяется.
Хочу тут разобрать некоторые технические аспекты.
Для начала прочитайте вот эти два поста от совершенно волшебного дядьки Луи Кесслера; я его блогом зачитываюсь уже который день: куча полезностей и важной информации.
http://www.beholdgenealogy.com/blog/?p=2700
А продолжение тут:
http://www.beholdgenealogy.com/blog/?p=2717
Если коротко, то вот, что он сделал. У него было аж пять своих аутосомных тестов: Ancestry, 23andMe, FTDNA, MyHeritage и Living DNA. Тесты были сделаны в разное время и что очень важно - на разных микрочипах. Вначале он проанализировал результаты на совпадение или различие снипов и убедился в том, что наборы определяемых снипов сильно отличаются друг от друга. То есть, результаты (снипы) каждого из тестов пересекаются с остальными лишь частично. Однако все же пересекаются. Эти пересечения позволили сделать ему первую важную вещь: определить для каждого из отдельных тестов так называемые "no-calls" (то есть те позиции, которые из-за случайных погрешностей эксперимента остались неопределенными; первоначально таковых в каждом из тестов было от 1 до 3 процентов) - из результатов других тестов, в которых эти позиции определились.
Это сразу резко уменьшило средний процент "ноуколлсов" в тестах.
Второй важный шаг - сличение совпадающих позиций (то есть тех, которые одновременно присутствуют во всех тестах). Это позволило ему выявить те позиции, по которым нет консенсуса по всем пяти тестам - и перевести такие сомнительные позиции в "ноуколлсы", разумно предполагая что они могли быть определены с ошибками.
Тем не менее, процент "no-calls" все равно остался низким, гораздо ниже, чем он был первоначально.
И наконец, на третьем шаге он объединил все результаты в один суперкит, в котором оказалось уже около 1,3 млн снипов - и загрузил его на GEDMatch. А на GEDMatch есть такой параметр, "overlap" (перекрытие). Эта величина показывает, насколько хорошо суммарно перекрываются позиции у совпаденцев (просто перекрываются, внутри них не обязательно совпадают снипы). Плохие overlaps GEDMatch красит в разные оттенки красного и розового. Это сигнал о том, что с большой вероятностью ваш совпаденец - ложный. И часто такой красно-розовый цвет возникает, если ваш совпаденец тестировался в другой компании. Хорошим же overlap считается при величине перекрытия больше 72000. Так вот, в полученном суперките Кесслер практически полностью избавился от красного и розового цвета - и практически все его совпаденцы в общем списке приобрели overlap больше 100000! Вдобавок, и количество совпаденцев заметно уменьшилось. А это значит, что таким способом он избавился от ложных совпадений, тех самых "false positives".
Ну хорошо, скажете вы, и познавательно. Идея понятна - но у меня нет пяти китов в пяти компаниях.
К счастью, есть и другие, более простые способы.
Ну вот, например, у меня: два теста, один от FTDNA, другой - от MyHeritage. Известно, что они очень похожи, снипы в них практически полностью совпадают, и следовательно, способ Кесслера подходит лишь наполовину: можно попробовать уменьшить количество "ноуколлсов", но стоит ли верить одному тесту (а не четырем другим, как у Кесслера)? А общее количество снипов не вырастет, поскольку оба теста по снипам почти идентичны.
Тем не менее, и тут есть способы улучшить качество (с точки зрения GEDMatch).
Но вначале напомню, что в GEDMatch есть один очень приятный инструмент. Называется он "People who match both kits, or 1 of 2 kits". Нас в нем будет интересовать нижняя часть результатов. В ней выводятся две таблички: это матчи, которые совпадают лишь с одним из китов, но не совпадают с другим. Как так может быть, если тесты почти идентичные? А вот именно из-за того, что скорее всего, эти совпадения ложные. То есть, уже сразу на этих совпаденцев можно не обращать внимания.
Но можно пойти и немного дальше.
Напомню, что не так давно GEDMatch мигрировал на другую платформу, которая первоначально называлась Genesis. Она содержит многие технические усовершенствования, которые долгое время обкатывались в режиме "беты" и вообще точнее, быстрее и лучше. Но есть один побочный эффект: старые киты, те которые были залиты на старый GEDMatch до миграции как бы потеряли часть своих снипов (это произошло из-за работы разного рода алгоритмов "выравнивания", здесь не будем вдаваться в совсем уж технические детали, отметим сам факт).
Так вот, я настоятельно рекомендую перезалить ваши старые тесты на GEDMatch еще раз, если вы этого после миграции еще сделали. Помимо того, что это восстановит снипы, "потерянные" в результате миграции, это еще и очень благотворно скажется на той самой нижней части инструмента "People who match both kits, or 1 of 2 kits". Кроме того, вы заметите еще две вещи: красно-розового цвета станет меньше просто визуально, и даже изменится порядок расположения ваших совпаденцев вплоть до верхней части таблички "One-to-many".
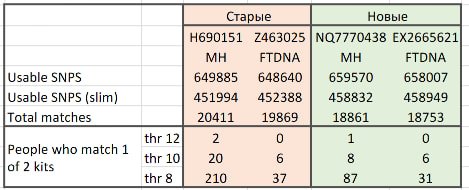
Кстати, результаты до перезаливки (старые, розовые) и после перезаливки (новые, зеленые) свел в простую табличку. Подчеркну, что "старые" и "новые" они лишь для GEDMatch; физически речь идет об одних и тех же raw-файлах. Для наглядности еще и разные пороги отсечения посмотрел (обратите, кстати, внимание, как быстро растет количество совпадений с одним из китов с уменьшением порога с 12 до 8 сМ).
В общем, судите сами.