
«Параллель Тучкова». Часть девятая, в которой появляется новый эксперт и сразу решает почти все задачи
Давайте теперь оглянемся назад. В решении нашей первоначально вполне исторической задачи мы с вами довольно далеко ушли от собственно исторического обсуждения в сторону математики и расчетных методов. Но зато нам удалось разработать довольно несложный метод определения широты главной параллели проекции Бонна с помощью простых и доступных инструментов. По ходу развития событий мы выяснили, что во-первых, нам нет необходимости использовать сложные формулы для сфероида и достаточно ограничиться простой моделью на сфере. Во-вторых, оказалось, что нелинейная задача хоть и поддается линеаризации, однако имеющийся набор расчетных возможностей стандартных офисных пакетов не позволяет ее решить таким способом. Эти же ограничения возможностей так и не позволили нам с вами ответить на очень важный вопрос: какова точность нашего разработанного метода? Или, говоря более строго, какова стандартная ошибка (или доверительный интервал) определенного нами параметра — широты главной параллели?
Поэтому в этой части я покажу, как можно было бы быстро и правильно решить задачу, если бы мы сразу [1] воспользовались еще одним инструментом: языком R.
УСТАНОВКА И ПЕРВЫЙ ЗАПУСК
Очевидно, что прежде чем начать пользоваться программой, ее следует установить. Тут нет никаких сложностей: программа, во-первых, бесплатная, а во-вторых, кросс-платформенная (а как вы помните из предыдущих обсуждений, именно на такие программы я и ориентировался в первую очередь). Установка тут происходит вполне стандартным для вашей операционной системы образом, никаких дополнительных условий при установке не потребуется. Единственное, что надо с самого начала понимать: нам с вами потребуются две различных программы: собственно язык R и надстройка над первой программой (интегрированная среда разработки, IDE), которая называется RStudio и представляет собой набор удобных инструментов для работы собственно с языком [2]. Поэтому и устанавливать эти программы следует именно в такой последовательности: вначале сам R, а уже затем — RStudio. Язык устанавливается со страницы главного репозитория R, который называется CRAN [3]. Здесь вам вначале предложат выбрать подходящий для вас локальный репозиторий по географическому принципу, а после выбора, на следующей странице, — необходимый для вас дистрибутив для вашей операционной системы (Windows, Linux, MacOS).
Установка RStudio еще проще, страница загрузки сама определит версию вашей операционной системы и предложит именно тот дистрибутив, который вам нужен [4].
При первом запуске RStudio вы увидите окно программы, разделенное на три части. Левая, самая большая — это консоль, в которой мы в дальнейшем будем вести основную работу: печатать команды и получать в ответ результаты. Назначение остальных частей окна станет понятным по ходу работы [5].
ПРОБНЫЙ РАСЧЕТ
Ну что же. Давайте эту работу и начнем. Поскольку у нас с вами уже есть исходные данные в созданной в предыдущих частях электронной таблице, логичнее всего ее и использовать, тем более что RStudio умеет с такими файлами работать — но... не совсем, что называется, «из коробки». Чтобы загрузить наши данные в RStudio необходимо воспользоваться верхним правым окном, в котором есть закладка «Environment». Здесь у нас будет появляться список всех наборов данных, которые мы загрузили в программу (в рамках текущей сессии), а также всех переменных, которые мы с вами создали. Нам нужна кнопка «Import Dataset» и соответствующий пункт выпадающего меню «From Excel...».
Так вот, при самом первом импорте xlsx-файла программа попросит нас установить некоторые дополнительные пакеты. С этим, конечно же, следует согласиться.
В данном случае необходимые пакеты устанавливаются и подключаются к текущей сессии автоматически, нам с вами ничего делать больше не нужно. За процессом можно наблюдать в основном окне консоли [6].
Тут я хочу задержаться на минуту и зафиксировать важные вещи, которые нам пригодятся в дальнейшей работе. Во-первых, установятся не только те два пакета, которые были указаны в предупреждении. Если найти на компьютере, что у нас на самом деле установилось, то мы увидим, что к нам «приехало» гораздо больше пакетов. Это происходит из-за того, что многие пакеты зависимы от других (а те, в свою очередь, тоже могут быть зависимы) [7].
Во-вторых, изучение этих установившихся пакетов показывает, что в качестве такой зависимости скачался пакет tibble. Это очень важный и полезный пакет, и сейчас я объясню почему, а работу этого пакета мы с вами будем наблюдать в течение всего дальнейшего изложения.
Табличные данные в R хранятся в объектах, которые называются датафреймами (dataframes). К датафрейму предъявляются определенные требования, например, данные в колонках (столбцах) должны иметь один и тот же тип внутри каждого столбца, количество данных во всех столбцах должно быть одинаково (но могут быть пропущенные данные) и так далее, тут я не буду подробно на этом останавливаться. Скажу лишь, что тиббл (tibble) — это такой усовершенствованный датафрейм, в первую очередь в отношении его удобного отображения в консоли: указывается его размер, отображаются лишь несколько первых его строк и только те столбцы, которые помещаются на экране консоли, а все остальное — показывается в виде своеобразного примечания под тибблом [8]. Немного ниже вы увидите, как это выглядит, а теперь вернемся к загрузке нашей таблицы.
Как только загрузятся необходимые пакеты (а в последующем — и сразу после выбора «From Excel...») у вас откроется окно предварительного просмотра ожидаемого импорта. Кнопкой «Browse...» вы выбираете нужный файл для импорта, после чего в окне отобразится первый лист xslx-файла. Под таблицей вы можете задать имя, под которым вы импортируете датафрейм (TP), с какого листа (в нашем случае это лист «Расчет по 3 меридианам») и желаемый диапазон ячеек для импорта. Нас с вами не будут интересовать вспомогательные столбцы с остатками и прочими расчетами, которые нам были нужны лишь для вычислений в Calc. Оставим только описательные колонки, широты и долготы (как в градусах, так и в радианах), а также измеренные углы в этих точках. Отметим также чекбоксы для чтения первой строки как заголовков столбцов и открытия импортированной таблицы в режиме просмотра. В первой строке с заголовками важно проконтролировать соответствие распознанного типа данных реальному и при необходимости скорректировать его. Обратите внимание: справа внизу под таблицей располагается окно «Code Preview», где в соответствии с изменением вами настроек меняется и набор команд будущего импорта.
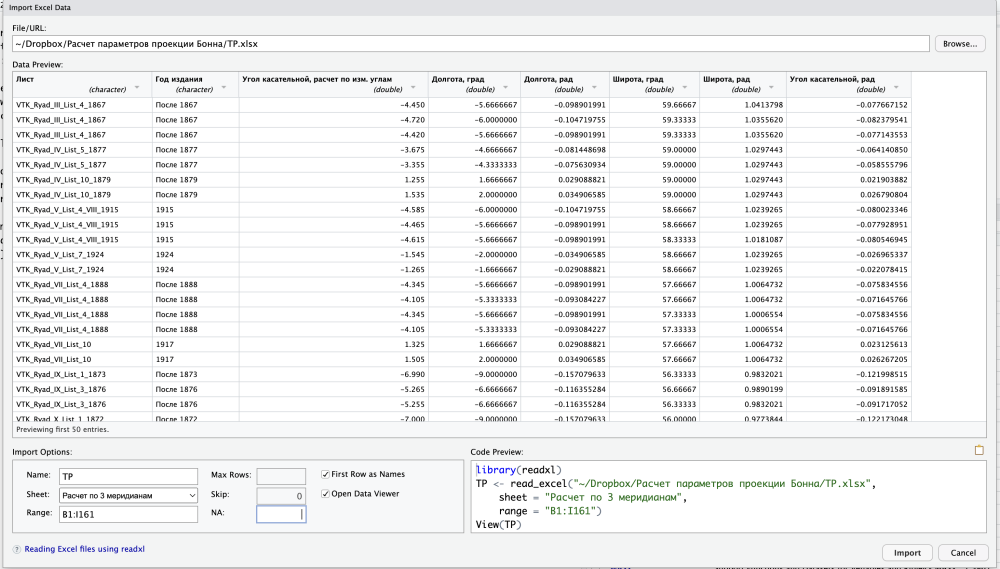
После нажатия кнопки «Import» этот набор команд запустится в консоли. Результат получится в точности таким же, как если бы мы печатали эти команды последовательно вручную.

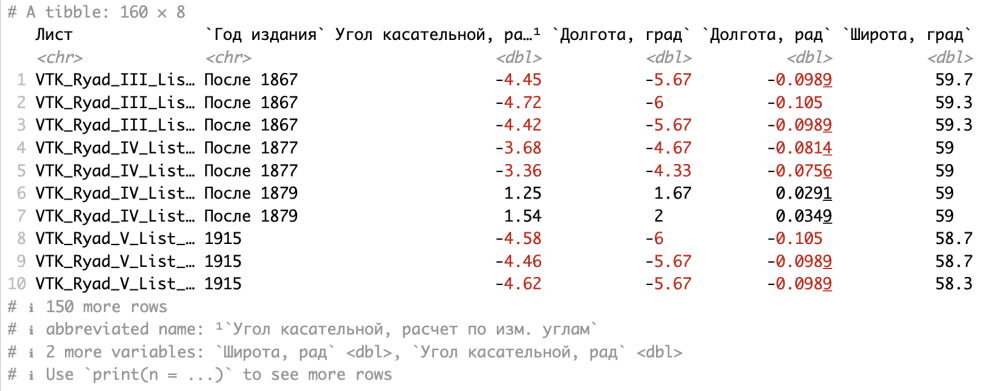
Поскольку мы отметили чекбокс «Open Data Viewer» команда View(TP) ввелась автоматически в набор, при этом наша импортированная часть файла отобразилась в режиме просмотра в верхнем левом окне рабочего пространства RStudio над консолью. Если же просто напечатать в консоли «TP», то импортированная таблица откроется прямо в консоли, причем в виде тиббла, о котором шла речь чуть выше.
Давайте сразу научимся сохранять такие объекты. Для файлов с данными в R предназначен специальный формат —.rds. Впрочем, возможности RStudio позволяют сохранить таблицу и в более привычных форматах, например, в .txt или .csv, однако только .rds сохраняет вместе с данными также их типы (например, текстовые или числовые), а также эффективно эти данные сжимает. Для сохранения таких файлов в R существует специальная команда saveRDS(), а для чтения, соответственно, readRDS(). Для примера я сохранил нашу таблицу-тиббл в файл TP.rds, затем загрузил этот файл в другую переменную TP2 и проверил переменные TP и TP2 на идентичность командой identical().

Обратите сразу внимание: как исходная, так и прочитанная таблица с данными у нас хранятся в созданных для этого переменных — TP и TP2 соответственно. Это очень важная особенность языка — хранить не только отдельные числа, слова или строки и т.д., но и объекты практически любой сложности внутри специально созданных переменных. Чуть позже мы с вами увидим, что в виде переменной можно сохранить целую модель регрессии! Это способствует тому, что любые команды или целые программы в R становятся более понятными и лаконичными.
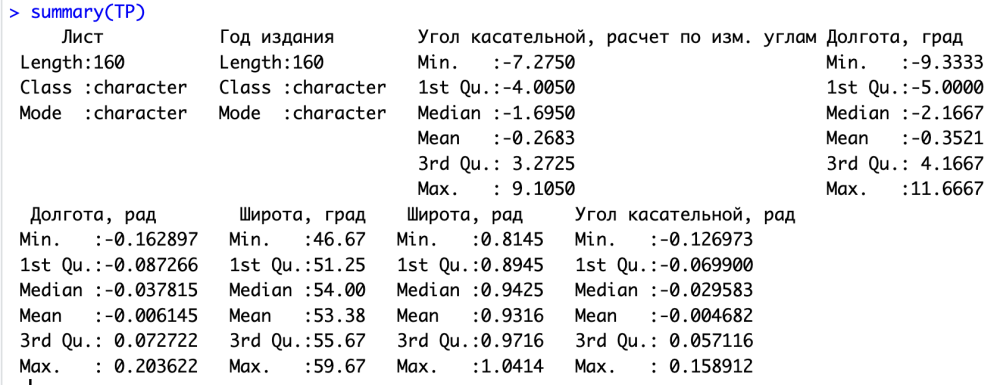
А чтобы посмотреть на то, что у нас хранится в какой-нибудь переменной, можно не только напечатать ее имя в консоли, как мы это делали выше, но и использовать одну из самых широко используемых команд языка — summary(). Результат работы этой команды как раз зависит от контекста, то есть от того конкретного типа переменной, к которой мы эту команду применим. Так, если мы применим ее к нашему тибблу, то команда выведет короткую описательную статистику по каждому столбцу таблицы.
Для вывода на экран или дальнейшего использования к отдельным столбцам таблицы можно обращаться так: TP$'Угол касательной, расчет по изм. углам'. Однако очевидно, что такое обращение слишком длинное и, в конечном итоге, если мы где-то будем использовать слишком много таких обращений, это приведет к очень громоздким и трудно воспринимаемым выражениям. Поэтому мы с вами пойдем дальше и извлечем из таблицы нужные нам данные, сохранив их сразу в виде отдельных переменных с компактными названиями. Делается это с помощью оператора присвоения <- (мы его видели раньше, когда импортировали xlsx-файл и читали файл .rds).
Обратите внимание, что нам нет необходимости печатать все название требуемого столбца целиком. Как только мы напечатаем знак $, RStudio сразу же поймет, что мы хотим и предложит список выбора имен столбцов.
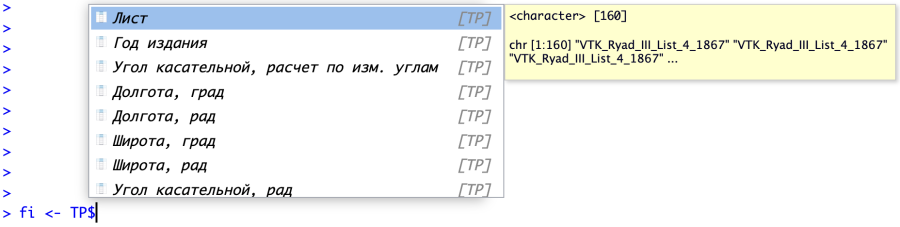
Таким образом создадим три переменных: fi, lambda и E в точном соответствии с нашей расчетной формулой. Для первого пробного расчета возьмем данные из таблицы в радианах, раз уж мы их все равно посчитали ранее.

После каждого такого присвоения будем выводить переменную на экран. Видно, что данные не просто извлеклись из таблицы, а извлеклись в том порядке, в котором в ней и хранились. То есть, каждое значение у нас стоит на том самом месте, которое соответствует исходной строке в таблице (номера этих мест написаны слева от данных в экранном выводе), причем это касается всех трех переменных.

Такой упорядоченный набор данных в R называется вектором и именно с векторами и происходит большинство вычислений в R. А порядок элементов, одинаковый для всех трех полученных нами векторов, имеет первостепенное значение для дальнейших вычислений.

Посмотрим теперь, что у нас с вами произошло с окружением (закладка Global Environment в верхней правой четверти рабочего пространства). В дополнение к нашему тибблу TP, там появились и новые переменные вместе кратким описанием того, что они собой представляют. Это значит, что мы с вами можем их использовать в любом месте и в любое время нашей текущей сессии [9].

И это время как раз у нас с вами и настало. Теперь у нас есть все, чтобы осуществить расчет нелинейной регрессии по неоднократно приводившемуся уже уравнению (2*):
E = λ*cosφ/(ctgφ(1) + φ(1) - φ) (2*)
Полностью текст статьи вы можете прочитать, посетив страницу автора на Boosty.